Some recent backtracking from what we have been calling "Microservices" has sparked anew the debate around that software architecture pattern. It turns out that for increasingly more software people, having a backend with (sometimes several) hundreds of services wasn't that great an idea after all. The debate has been going on for a while and much has already been said, but there are still a couple of things I'd like to say.
TL;DR "Microservices" was a good idea taken too far and applied too bluntly. The fix isn't just to dial back the granularity knob but instead to 1) focus on the split-join criteria as opposed to size; and 2) differentiate between the project model and the deployment model when applying them.
I explain. Allow me to rant a bit first.
Contents
How we got here
There were three main reasons for the initial success of microservices as an architectural pattern for software: 1) forced modularisation, 2) weakened dependencies, and 3) an excuse for having no architecture. In order:
-
In the monoliths of old, you could in theory enforce module boundaries. You could say that your
acme-helpersoracme-data-toolscould not depend onacme-domain, say, and you even had some tooling to enforce that, but it was fallible. Especially in big companies where these monoliths spanned more than a team's cognitive horizon, violations of those boundaries were often a simpleimportaway, and of course rife. Angry architects saw in microservices the promise of making those a thing of the past: now the developer is forced to only deal with the API. Codebases parted ways and calls were made to go down the network stack and back. -
So then, one wouldn't depend on a fellow service at build time, only at runtime. Great. Method calls became http calls. "Now we don't need to care about dependencies" — actual people said this, as if the dependency wasn't fundamental and instead just an accidental artifact of the build setup. Everybody brushed up on their HTTP and different server and client implementations, read all about REST and Soap (and RPC, RMI and CORBA while at it) and merrily created a layer of indirection between modules — now services — that was very loose. Typed APIs, granular network policies and contract testing came much later.
It felt liberating until the complexities of API versioning, delivery semantics, error propagation, distributed transaction management and the sprawl of client code in all callers of a service began to show up. This was a gigantic shift right, but hey, the build process was simpler.
-
More insidious perhaps was the validation that "doing microservices" brought to organisations that lacked a thesis about how their architecture should be. There was now a sanctioned answer to most architectural dilemmas: another microservice. Another entry in the service catalog for any and all interested parties to call. This ecology of interacting parties, each acting in their own interest for the common good spoke to an underlying, tacit belief that the emergent mesh of services would approximate the latent natural architecture of the domain.
So soft and convenient was the lure of not having to draw hard architectural lines that we got lazy where we weren't and accepted our laziness where we already were. If you didn't subscribe to that belief, the problem was you and your lack of understanding of complex systems, you objectivist cretin.
Yes, there was real pain in managing monoliths and sure, many systems were too monolithic (i.e. had deployables too large) but the zealotry of a newfound purity swung the pendulum too far, as they always do. Not only do we not need to run so many services so small, we also don't benefit from isolating their codebases so much. To summarise:
- having a big flat permissive build is no good reason to split deployables;
- weakening dependencies between different parts of our systems is a "shift-right" loan with high interest; and
- having a ready answer when the thinking gets tough is a soothing lie that just moves complexity about. There is no substitute to the effortful application of cognitive power to a problem.
What now?
Two things: focus on the right criteria for splitting a service instead of on its size, and apply those criteria more thoughtfully.
Size is not the answer
The micro in microservices ought to be at best a prediction, never a goal. We may predict services will be micro but they don't have to be. Vaugh Vernon is right when he speaks about "cohesion for a reason".
There should be no prescribed a priori granularity of services. There is no prescribed size of a service. There are instead good and bad reasons to split parts of a software system.
So the heuristic is:
Start one, split with a reason.
Conversely, if a reason ceases to exist, consider joining them.
The missing hinge
There are however different realms in which "software systems" exist: they exist both as artifacts we interact with and as artifacts computers interact with. Code and binary. We organise them in different ways: the project model (repositories, projects, modules and their dependencies) and the deployment model (what production environments look like and how deployables run in them).
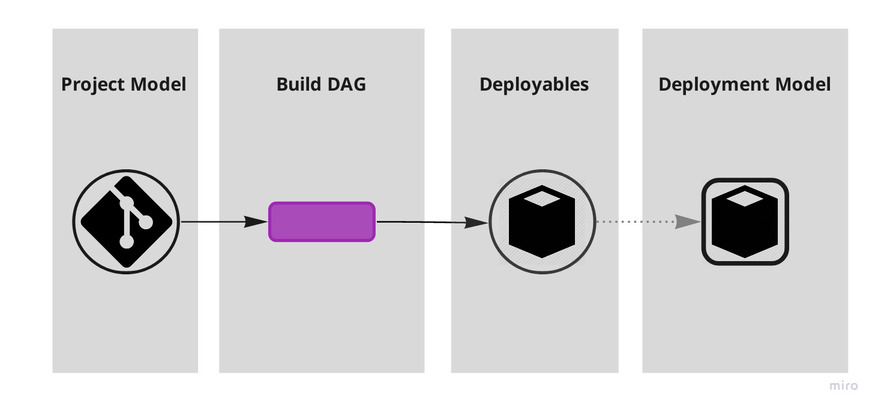
In the process of going from coarse to granular (i.e. from monolith to microservices) however, little attention was paid to the difference — and possible indirection — between those two models. The hammer hit both fairly indiscriminately and made us split codebases because of runtime concerns and split deployables due to project concerns.

Much like stiffness in a part of the human spine can result in pain in another, stiffness in our build DAGs is causing excessive mirroring between our project and deployment models; between our repositories and our services; between the way we organise our code and the way our services run. That mirroring is on the one hand preventing us from shifting left concerns about the relationships between modules that have often been made weak and fragile runtime dependencies, while on the other hand encouraging us to have more services than what the runtime reality would call for. That brings pain.

Central to resolving this stiffness is the realisation that the build flow, at least conceptually, is a DAG – Directed Acyclic Graph – where the nodes are jobs and versioned artifacts and the edges connect either a job to a versioned artifact ("produces") or a versioned artifact to a jobs ("dependency_of"). Deployables are by definition the versioned artifacts that are consumed by the deployment jobs.
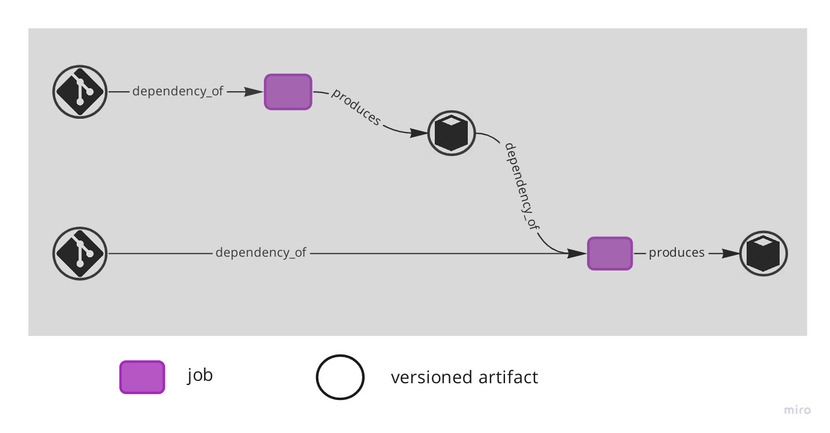
For too long we overlooked how much a flexible and frictionless build DAG allows us to improve our architecture on both sides. With moderately rich build patterns we can have our code where its intent is clearer and more constraints can be validated at build time and still have it deployed into its simplest viable form, running where its execution is cheaper, faster and safer.
 .
.
Why so stiff, bro?
I'm not sure what the historically accurate account is that would explain the excessive simplicity of build patterns across the industry. I do know from experience that too many practices make do with very simple and linear flows where one repository builds independently one and only one service. Regardless of the legitimate argument about code duplication and its tradeoffs, there seems to be an aversion to build-time internal dependencies, even when these bring in clearly desirable data or logic such as message format definitions.
I suspect it might have something to do with how very few CI tools support composition natively (i.e. the outputs of jobs being able to be the inputs of others), how fallible semantic versioning in practice is and the difficulty of automating deterministic version propagation.
By that I mean keeping local copies in sync with CI, builds repeatable, and new upstream versions automatically used by their downstream dependents. It isn't trivial and requires some versioning and build-fu that, to my knowledge, most practices end up shortcutting to either sacrifice repeatability by using latest or stifling the flow by requiring repeated manual work. Hence the pressure to have a simple build setup.
The exact cause is unimportant though. What is important is that overcoming this is crucial.
Split-join Criteria heuristics and smells
Many criteria for splitting or joining software systems, ranging from the social (teams, bounded contexts) to the mechanical (cpu or io boundedness) have been put forth, and they all make some form of sense. However, most of them are either a good reason to split projects or modules, or a good reason to split deployables, rarely both. Keeping that in mind will help us apply them more effectively.
Below are a few possible criteria and some comments about their application. I'm not trying to be exhaustive, just illustrating the kind of reasoning makes sense to me.
Runtime, deployment side criteria
-
Different Runtime – If a part of the codebase compiles to a different runtime it becomes a different deployable and we call it a different service.
-
Elasticity Profile – Some parts of the system may have a spikier load profile. It might pay off to have them scale in and out separately from the rest.
-
Load Type – Some parts of a generally latency-oriented io-bound system may generate occasional peaks of cpu-bound load which can hurt response times. It might be better to put them in a different compute infrastructure perhaps more cpu-heavy and oriented for throughput instead.
-
Security – Some parts of the system may deal with more sensitive data or a set of more privileged users, while some others may even be public. If the burden of security for the parts that need it on the parts that do not is considerable (and that includes unknown risk), then it might pay off to have them separate.
-
Process Disposability – Ideally most parts of our systems would cope well with replicas being terminated in one place and spun up in another. If some parts do not, maybe because they have long-lived transactions that keep unreplicated state, it might pay off to separate them, depending on your reliability profile and your process scheduling churn.
-
Availability Requirements – Some parts of the system may be ok with being terminated, either because they're not time sensitive and can resume or because they're not that important. It may pay off to have these run on cheaper less reliable infrastructure like spot-instances or on-prem servers.
-
Process Replication – If some parts of your system cannot function correctly in a distributed way, forcing you into a single-replica active-standby deployment (at best) then you better minimise the amount of logic that sits on that single point of failure.
-
Reliability – If an important service has its reliability compromised by one misbehaving module that for whatever reason can't be easily improved, it might be preferable to split them.
-
Blast Radius – Similarly, a service's surface area might so large that however reliable it may be the impact on availability is too wide.
-
Dependency Hell – Some runtimes have a flat address space where all modules are linked equally regardless of their dependency path (JVM we're looking at you). When the same module is brought in twice or more, it has to be unique and work for all its dependents, so a single version needs to be chosen. Although keeping up with recent versions, binary compatibility across minor versions of libraries, and tools that namespace different versions of a module do alleviate the burden of solving those version constraints repeatedly, sometimes it might be big enough to warrant splitting the deployable and cut the dependency graph in two.
As you can see, these are all about the reality our production processes encounter when actually running, and the tensions radiating from that. Keeping in mind the indirection between the project model and the deployment model the build DAG can give us, we see that in most if not all instances, little reason would there be to split codebases.

A monolithic setup hammered by deployment-side splits thus results in several services, in an approximately optimal arrangement for their execution, but not necessarily in several independent codebases.
Build time, project side criteria
-
Rate of Change – The more volatile should depend on the least volatile. This is the well known Stable Dependencies Principle. To "depend in the direction of stability" helps contain the volatility inherent to systems that change.
-
Doing more than one thing – The often evoked adage of "doing one thing and one thing well" is scale-invariant and thus borderline meaningless. The thing can be big or small and still be one. A service can do "billing" or "persist the serialised invoice": both are one thing. Furthermore, there's nothing fundamentally wrong with doing more than one thing.
The call graph of a service being partitionable (a workable definition of more than one thing?) may be a good reason for modularising things on the code side, but no more than a mere sign that valid reasons for splitting the deployable may exist.
-
Different bounded contexts – Some parts of your system may solve a different kind of problem and thus require a separate vocabulary. Where these different parts touch there will be translation of data from one domain object to another. None of this implies that both ends of that translation have to be different services. We do it all the time with libraries.
Vaughn Vernon suggests starting with bounded contexts, more as a heuristic rather than a definite rule, but I still object on two counts: we shouldn't aim for a particular ballpark size for services just because it feels right, nor should we rely on heuristics and "proxy reasons" when we can have hard criteria.
-
Build Times – When too much is part of the same build the inconvenience of building the same modules all over again for any change in others becomes a pain. This is a good reason to split a build, i.e. make some modules build separately from others and have the dependencies between them be version-specific (external) instead of direct (intra build). It is not a good reason to change the way things run. See Dependency Hell however.
-
Release Size and Cadence – When the integration of changes from different projects and modules delay releases, one has a problem with one's CD setup (test coverage, dependency direction, semantic versioning, …?), not a problem with one's architecture. It may be worthwhile to split one or two services to alleviate the pain while the root problem is fixed. But, just like a wound drain is sometimes medically necessary even though it's not the skin that is lacking an opening, let's be conscious that splitting deployables for this reason remains only a tactic.
-
Different teams – The relationship between team structure and software architecture is strong. Conway's law is real, the inverse Conway maneuver works, but they relate patterns of communication among people and groups of people with the boundaries between "systems" taken as things "people work on" or "have concerns over" not necessarily "things that get deployed".
For this one to be a valid deployment-side reason (i.e. "different teams" to imply "different services"), the coordination effort and the added cognitive load due to the shared concerns that would disappear with a split would have to be high enough to make up for the cost of splitting them. That would typically happen if there are differences on the later stages of testing, deployment, observability and support. Most of those concerns are absorbed by transversal platform teams that provide self-service operations or fall into a support rota that generally is a subset of people dealing with shared operational concerns already anyway. As with all things dealing with humans, add salt.
-
Different language – as long as different languages compile satisfactorily to the same runtime (like say, Java and Scala) different modules written with them can be part of the same service. Again, we do it all the time with libraries.
Conversely to previous section, the above are criteria that pertain more to the reality we humans encounter when working on our systems and the tensions radiating from that. Again keeping in mind the project-deployment indirection, we see that little reason would there be to split deployables. Instead, these are criteria for different arrangements of modules, projects, their dependencies and the ways they compose into deployables.

A monolithic setup hammered by project-side splits would result in one where repositories, modules and their dependencies are broken down into an arrangement that creates the least tension when operated by humans, without creating unnecessary complexity on the deployment side.
Suffice for this article to consider the project model as whole. I wish to leave the details of the ideal arrangement of repositories, projects, modules and dependencies to another post.
Heuristics and smells
-
State – If you don't have state, just pure logic, you probably have a library, not a service. If you have state, but it doesn't change with user requests what you have is configuration, either global or environment-specific. If changes to configuration are not time-sensitive, it can be a parameter to the deployment, which gets triggered when it changes. If they are time-sensitive you might need a configuration service that serves them continuously, rarely a bespoke one. If you do have global state that can change with, and across requests, you may have a service.
-
Cookie Cutter – Having a project template to aid in creating new microservices is indeed helpful. Maybe too helpful.
-
API Trees – Looking at the call graph, neat trees where the top service gets called by many, and the bottom ones only called by their parents, especially if they're segmented by some business concept, are a smell that deployables have been split according to a romanticised view of their role instead of hard criteria to do with their computing reality.
These are the easiest to join up. Often their data is related by stable identifiers already so data migration is minimal, easy or unnecessary.
Examples
As a thought provoker, here are some patterns illustrating how, with some flexibility in the build DAG, we might organise our systems in ways that suit well both humans and machines. I have left out the testing and promotion that happens on the path to production to, maybe, another post.
-
Policy Plugin pattern – Build flow that supports the strategy pattern, where an algorithm instance has to be chosen at runtime.
Let's say we have product a, b, c and billing. At runtime billing gets events from each of the others. It has its own billing cycle and a batch style, throughput-oriented workload. The others are more transactional, always-on and latency-oriented. Billing knows how to issue invoices in general but does not know all the particulars of each product. Each of the others knows all about their product only.

Based on logic that comes from each of them separately at compile time (i.e. billing has a compile-time dependency on the other projects for the artifacts that define the invoicing logic) it can discharge its duties by calling the right piece of logic at runtime.
I don't want to strawman anyone here, but I can see this scenario being implemented in microservice-oriented practices with either:
- more service calls at the point of product-specific invoice logic, possibly hammering other services during the batch jobs' execution and creating deployment coupling, or forcing another split because of cycles; or
- with product-specific logic in the billing codebase, creating development friction.
-
Server-supplied client libraries – Not exactly about the split-join criteria but a good demonstration of non-linear build flows. Instead of having each caller of a service implementing (a subset of) their interface, keeping that up-to-date, and stub its behaviour in their tests, consider instead having each service providing that as a library: the interface, the client implementation and the test stub.

The contract surface becomes compile-time checked, the wire protocol becomes controlled by the called service's team, there is no duplication of client-side implementations with associated drift or accumulated cruft over time, and we get stubs that actually mimic the service's behaviour. Rand Davis has been beating this drum (article, presentation).
We don't have to go all-in with the sharing between caller and called: even if we only share the API or data format definitions this pattern stays pretty much the same in what concerns the build flow.
-
External service proxy – When there is an external service our systems need to call, we often want to façade and to proxy it, in order to shield ourselves from their vocabulary, irrelevant idiosyncrasies and failures. It will typically only be available for production and one other pre-production environment, not for each of our environments.
A common pattern is to have a proxy (or adapter) service that gets deployed either in bridge or stub mode, according to whether that external counterparty exists for that environment. This adapter service is what all others call.
In most cases however, the adapter service does not hold cross-transaction state and we can have a simpler setup where two artifacts are built: the client library for the external service that becomes a dependency of all the callers, and the deployable that mimics the external service in environments for which it is not available. There's one less hop in the call graph.
-
Testing monolith – In the earlier stages of testing we're generally more concerned with the functional aspects of our systems. It would be useful to be able to test the end-to-end functionality of our applications in a way that is abstracted from the deployment particulars.
Having a self-contained executable that is functionally equivalent to a set of services, comprised of all their meaty parts and none of the boilerplate, where calls to their interfaces are short-circuited (or mediated, for fault-injection purposes) to actual implementations (modulo in-memory data stores etc), allows tests that are only concerned with functional correctness to run faster and span more widely without requiring a full deployment. Property testing for example, can be made much more effective. End-to-end in-browser demos become possible if we can target
wasmorjsruntimes (and the threading model differences don't ruin the party).
Conclusion
There are build patterns that give us total control over the relative visibility between components and over how they compose into deployables. One build to many deployables, many to one or anything in between is possible. Shifting concerns left helps us build better software. An earlier error is a better error. Constraints liberate.
The tensions and constraints that shape the arrangement of our projects, modules and dependencies are of a different nature than those shaping the arrangement of our deployables. A little build-fu goes a long way in combining development friendliness with mechanical sympathy.
There's no such thing as a microservices architecture, there is software architecture. The size and granularity of services are a dimension of the solution, not a given of the problem. To dictate it from the start is reductive and only shifts complexity elsewhere.
Edit (30/09/2020): added paragraph and image clarifying the build DAG concepts.